robots.txt for Roofing Websites
A robots.txt file is a plain text file at the root of a roofing website that tells search engine crawlers which paths they may and may not request. One misplaced line can block the whole site from search.

Free robots.txt Audit
Many roofing sites carry a robots.txt rule that quietly blocks service or city pages. Get a free audit that lists every blocked path and a plan to reopen crawl access.
What Is a robots.txt File?
A robots.txt file is a plain text file at the root of a roofing website that tells search engine crawlers which paths they can and cannot request.
Lives at One Fixed Path
A crawler looks for the file at the domain root, such as yourdomain.com/robots.txt, and reads it before it requests any other page.
Controls Crawling, Not Indexing
The file decides which paths a crawler may fetch. A page Google never fetches can still be indexed from external links, so robots.txt is not a way to hide a page.
A Public File
Anyone can read a site's robots.txt, so it adds no security or privacy. It guides crawlers and nothing more. See technical SEO for roofers.
Why Does robots.txt Matter for Roofing Websites?
robots.txt matters because a single blocking rule can keep Google away from the service and city pages that produce roofing leads, and the failure leaves no error in analytics.
A Block Happens Before Crawling
- A broken link returns a 404 that shows in analytics; a robots.txt block stops the request before any of that.
- The site looks normal to a visitor while Google never reaches the blocked pages.
- A wrong rule can sit live for months without an obvious symptom.
It Directs Crawl Effort to Lead Pages
- Google gives each site a limited crawl budget, so where that effort lands matters.
- Closing admin and duplicate paths leaves room for the crawler to reach service and city pages.
- Steady crawl access to city pages supports stable local rankings and a steady lead flow.
How Does a robots.txt File Work?
A robots.txt file works through groups of rules, each naming a crawler and the paths that crawler may or may not request. The crawler reads the file, then follows the rules that apply to it.
The Four Directives Roofers Need
- User-agent names the crawler a rule group applies to, with an asterisk meaning all crawlers.
- Disallow lists a path the crawler should not request, such as /wp-admin/.
- Allow reopens a path inside a disallowed folder, such as an image directory.
- Sitemap declares the full URL of the XML sitemap.
Rules Match by Path Prefix
A Disallow rule matches every URL that starts with the listed path. "Disallow: /services/" blocks the whole services folder, including every service page below it, which is why a careless rule reaches so far.
A Hidden Block Stops the Lead Flow
When a robots.txt rule blocks the pages that rank for roofing searches, calls and form fills fall while the site still loads fine for visitors. We find the rule and reopen the path.
Call Now For a ReviewOr call +1 272-207-3231
How to Avoid Blocking Important Roofing Pages?
Avoid blocking important pages by disallowing only admin and duplicate paths, and never the folders that hold service, city, or emergency pages. List the exact paths to close rather than broad patterns.
Paths That Are Safe to Disallow
- /wp-admin/ and other dashboard paths a visitor never sees.
- Internal search result pages that create thin, duplicate URLs.
- Cart, checkout, or thank-you paths with no search value.
Paths to Keep Open
- The /services/ folder and every roofing service page below it.
- The /locations/ or city folder that carries local rankings.
- The CSS, JavaScript, and image files Google needs to render and judge the page on mobile.
How Does robots.txt Work With the XML Sitemap?
robots.txt and the XML sitemap work as a pair: the sitemap names the URLs to crawl, and robots.txt sets which paths a crawler is allowed to fetch. The two must agree, or they send Google a mixed signal.
Declare the Sitemap in robots.txt
A Sitemap line with the full sitemap URL points a crawler to the list of pages a roofing company wants indexed. See XML sitemaps for roofers for how to build that list.
Keep the Two From Conflicting
A URL listed in the sitemap but disallowed in robots.txt sends a contradictory signal. Remove a page from the sitemap if it should stay closed, or reopen the path if the page should rank.
robots.txt vs the noindex Tag
robots.txt and a noindex tag solve different problems: robots.txt controls whether a crawler may fetch a path, while a noindex tag tells Google to keep a fetched page out of the index.
Use robots.txt to Manage Crawl
Disallow paths that waste crawl budget, such as admin folders and duplicate URLs. A disallowed page can still appear in results from external links, so it is not a way to remove a page.
Use noindex to Keep a Page Out
To keep a page out of search, leave the path crawlable and add a noindex tag so Google can read the instruction. A page blocked in robots.txt may never be fetched, so Google never sees the noindex.
Common robots.txt Mistakes Roofers Make
Roofing sites lose search visibility through a short list of robots.txt mistakes, most of them carried over from a template or a staging build.
Blocking and Staging Errors
- Disallowing /services/ or /locations/, which removes the lead pages, often copied from a generic template.
- Leaving a staging rule that blocks all crawlers live on the production site after launch.
- Blocking /wp-content/, which keeps Google from the CSS, JavaScript, and images it needs to render the page.
Parameter and Coverage Errors
- Blocking URL parameters used by service or location filters, which hides page variations.
- Blocking the parameters on emergency or storm-response pages, so those variations go undiscovered.
- Editing the file without a change log, so no one can trace which edit caused a drop.
How to Audit a Roofing Site's robots.txt?
Audit a robots.txt file by reading the live file, mapping it against the pages that should rank, and confirming Google can reach each one. Run the check after every site change.
Read the Live File
Open yourdomain.com/robots.txt and list every Disallow rule, then note which folders each rule reaches.
Map It to Key Pages
Check that no service, city, emergency, or blog path falls under a Disallow rule, and confirm the Sitemap line is present.
Confirm in Search Console
Use the URL inspection and crawl reports in crawlability checks to verify Google reaches the pages that matter.
A Recovered Site Earns Back Its Leads
A roofing site left fully blocked through a redesign can lose months of rankings before anyone notices. Reopening crawl access and rebuilding coverage protects the lead pipeline.
Call Now For a ReviewOr call +1 272-207-3231
Proof of Performance
Results from roofing campaigns that rank in local search.
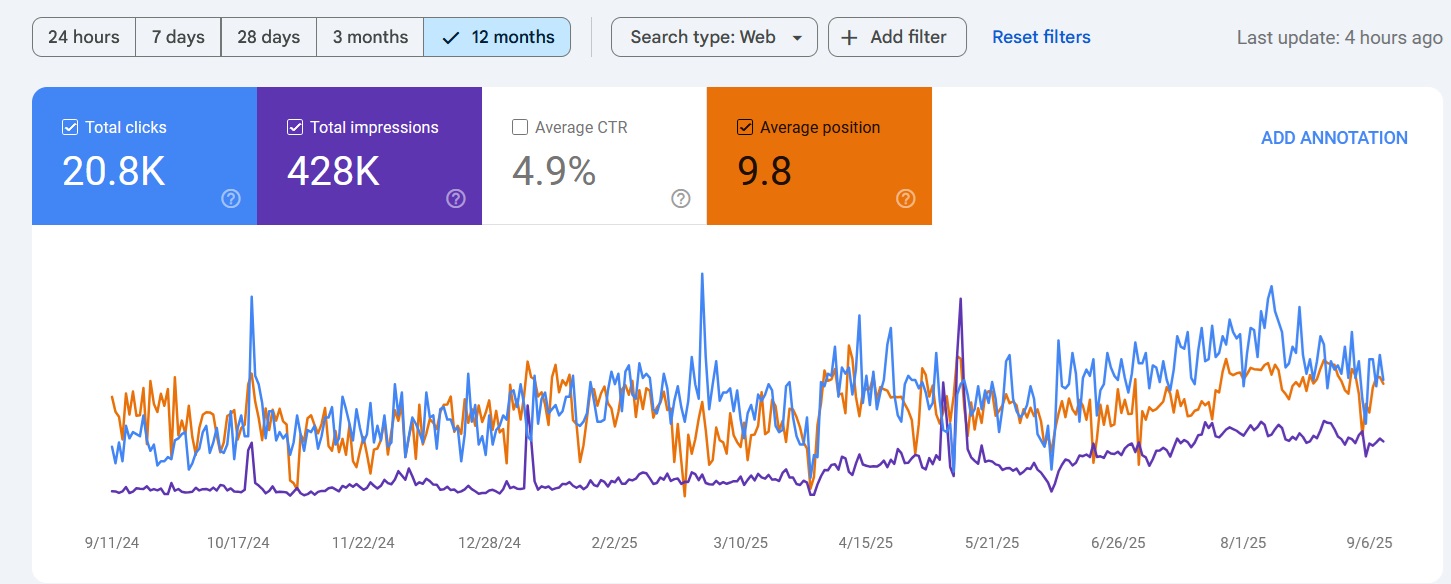
Map Pack Rankings
Ranked in Local Search Within 90 Days
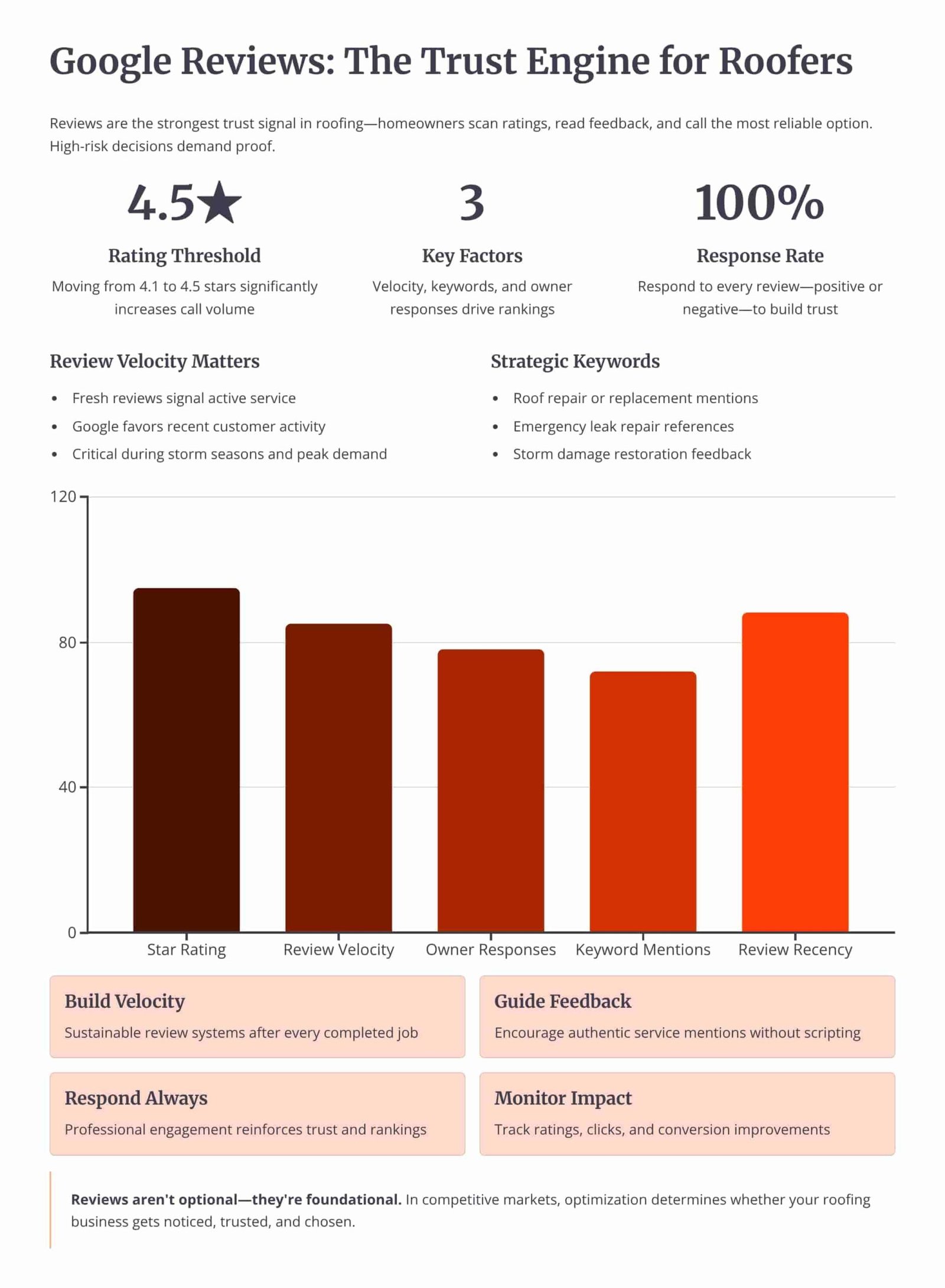
Review Velocity
150+ 5-Star Reviews Generated
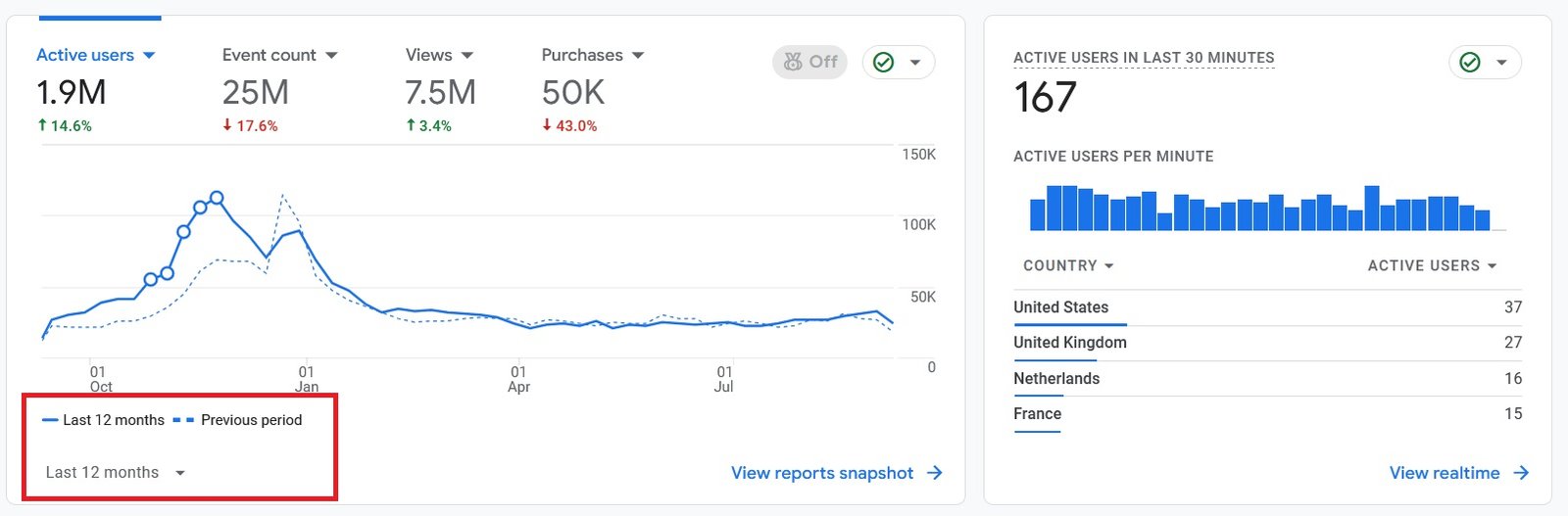
Organic Traffic
300% Increase in Qualified Traffic
What Roofers Say
The 180-Day Roofing SEO Roadmap
See how we optimize the profile, build the website, and earn local-pack rankings over a 6-month engagement.
Month 1: Profile Audit and Setup
- Category and Field Fixes: Setting the primary category, secondary categories, description, services, and service areas.
- NAP Cleanup: Correcting the name, address, and phone number across the profile, the website, and the directory citations.
Month 2: Reviews and Media
- Review System: Setting up a steady request flow and replying to every review, positive and negative.
- Photo and Post Cadence: Uploading job photos from each completed roof and publishing profile posts twice a month.
Month 4: Citations and Site Support
- Citation Building: Adding consistent listings on the directories that feed prominence for a service area.
- Service-Area Pages: Building city pages on the website that reinforce the profile's service areas.
Month 6: Local-Pack Rankings and Leads
- Map-Pack Position: Reaching the top 3 of the local pack for core roofing queries in the served cities.
- Lead Tracking: Measuring calls and direction requests from the profile against the cost of paid leads.
Owning Search Demand vs Renting It From Lead Platforms
If you pay Angi or Google Ads, you are renting visibility. The moment you stop paying, your pipeline dries up. Ranking the profile and the website for high-intent local searches builds permanent digital equity.
Shared Lead Platforms (Angi, HomeAdvisor)
- The Race to the Bottom: Shared leads force you to slash prices to win against 5 other roofers.
- Low Intent: Half the time they aren't ready to buy, they were just clicking around online.
Local Search SEO (Our Approach)
- 100% exclusive, direct-to-you inbound calls.
- Highest closing rate. They chose YOU from the local pack.
- Compounding ROI. You don't pay per click.
We Identify Search Intent Using Industry-Leading Data Tools




Expertise Built on Data.
Not Guesswork.
I'm Nizam Ud Deen, and I don't build generic websites. I build search intent engines specifically for the roofing industry.
For years, I've watched roofers burn money on agencies that brag about "traffic" while the phones stay silent. Traffic without intent is worthless. My system maps exactly how homeowners search during storms, when comparing prices, and when they're ready to buy, and intercepts them at every stage.
The No-Brainer Roofing SEO Guarantee
We don't guarantee "traffic" or "rankings." We guarantee high-intent leads.
"We guarantee to generate 15 exclusive, inbound replacement or repair leads per month within the first 180 days, driven entirely by high-intent organic search. If we don't hit that metric, we work for free until we do."
Measuring Success: Leads and Revenue
We don't report on vanity metrics. If traffic goes up but revenue stays flat, the strategy failed. We track the pipeline.
Call Tracking
Every keyword mapped to the exact phone call it generated.
Form Fills
Tracking estimate requests from high-intent local landing pages.
Booked Jobs
Connecting CRM data to SEO efforts to prove actual revenue return.
Cost per Lead
Monitoring organic CPL to ensure it beats shared platform costs.
The robots.txt Audit Checklist
Run the roofing site's robots.txt through this checklist to confirm the file guides crawlers without closing a lead page.
Frequently Asked Questions
Clear answers about robots.txt for roofing websites.
What is a robots.txt file?
Where does the robots.txt file go?
Does robots.txt stop a page from being indexed?
What should a roofing site disallow in robots.txt?
How does robots.txt work with the XML sitemap?
What is the difference between robots.txt and noindex?
Can robots.txt hurt my roofing rankings?
Why should a roofer not block wp-content?
What is a staging robots.txt and why is it dangerous?
Should a small roofing site even have a robots.txt?
How do I test a robots.txt file?
How does robots.txt affect crawl budget for roofers?
How often should a roofer review robots.txt?
Get Your Free robots.txt Audit
We'll read the live robots.txt, map it against the pages that should rank, and show you exactly which paths the file blocks.
What You Get:
- Blocked-Path ReportA list of every Disallow rule and the folders it reaches.
- Lead-Page Crawl CheckConfirmation that Google can reach the service and city pages.
More Deliverables
- Sitemap Alignment CheckA scan for sitemap URLs that the file disallows.
- Corrected robots.txt DraftA clean file that closes admin paths and keeps lead pages open.
Claim your free robots.txt audit today. No commitment required.